GPT-5.3 Codex 대 Opus 4.6: 우리는 프로덕션 Rails 코드베이스에서 두 가지를 모두 벤치마킹했습니다. 결과는 잔인했습니다.
우리는 Claude Code와 Codex CLI 에이전트를 모두 사용하고 좋아합니다.
SWE-Bench와 같은 공개 벤치마크는 코딩 에이전트가 자신의 코드베이스에서 어떻게 수행되는지 알려주지 않습니다.
예를 들어, 우리의 코드베이스는 Phlex 구성 요소, Stimulus JS 및 기타 특이한 선택 사항이 포함된 Ruby on Rails 코드 베이스입니다. 한편 SWE-Bench는 모두 Python입니다.
그래서 우리는 자체 SWE-벤치를 만들었습니다!
**방법론:**
1. 우리는 훌륭한 엔지니어링 작업을 대표하는 PR을 리포지토리에서 선택했습니다.
2. AI는 각 PR에서 원래 사양을 추론합니다(코딩 에이전트는 솔루션을 볼 수 없습니다).
3. 각 에이전트는 독립적으로 사양을 구현합니다.
4. 세 명의 별도 LLM 평가자(Claude Opus 4.5, GPT 5.2, Gemini 3 Pro)는 각 구현의 **정확성**, **완전성** 및 **코드 품질**을 기준으로 등급을 매깁니다. 단일 모델의 편향은 없습니다.
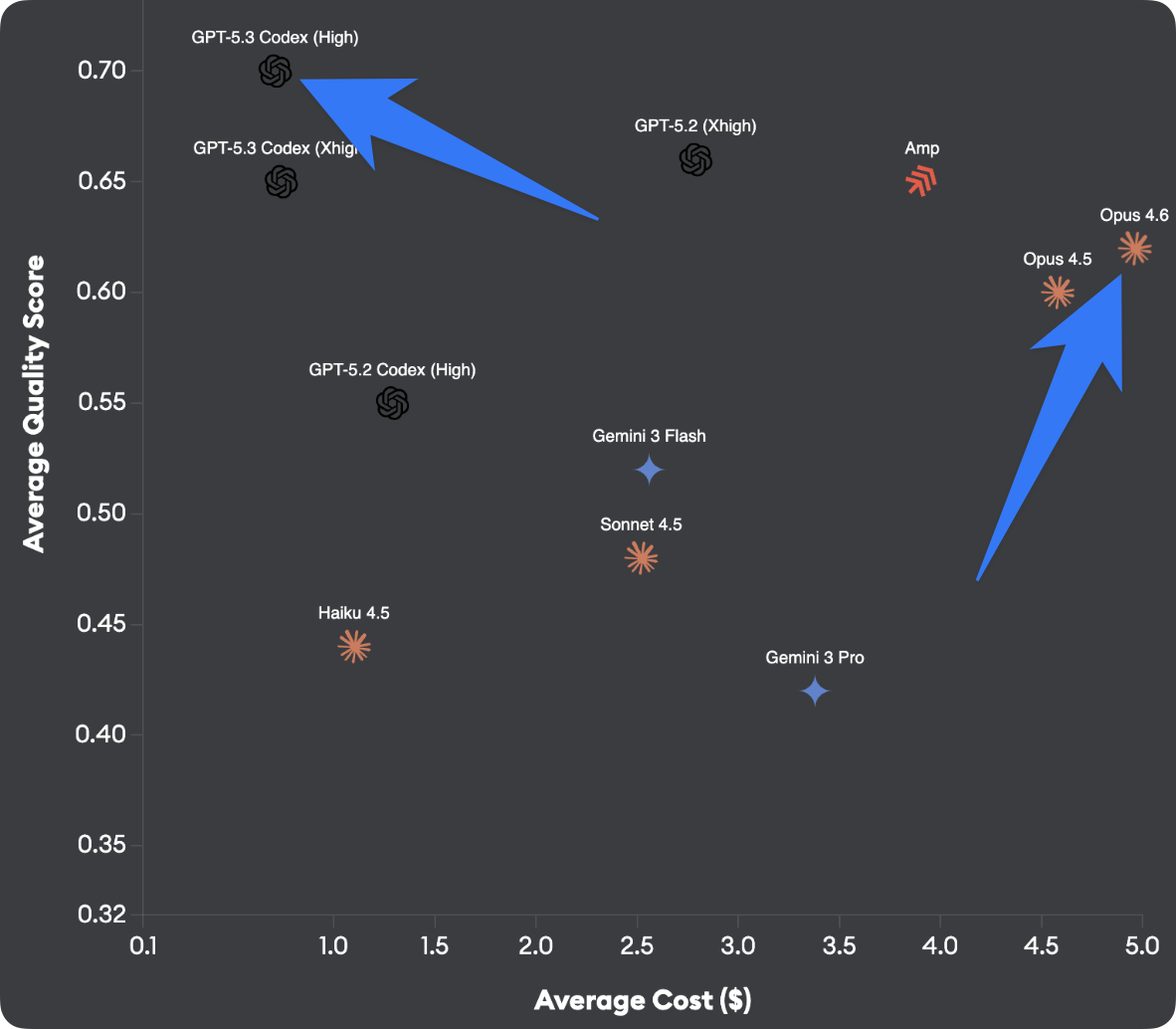
**제목 번호** (이미지 참조):
* **GPT-5.3 Codex**: 티켓당 $1 미만에서 ~0.70 품질 점수
* **Opus 4.6**: ~$5/티켓으로 ~0.61 품질 점수
Codex는 약 1/7 가격으로 더 나은 코드를 제공합니다(API 가격이 GPT 5.2와 동일하다고 가정). Opus 4.6은 4.5에 비해 약간 개선되었지만 비용에 비해 압도적입니다.
다른 에이전트(Sonnet 4.5, Gemini 3, Amp 등)도 테스트했는데 전체 결과가 이미지에 표시되었습니다.
**자신의 코드베이스에서 이것을 실행하세요:**
우리는 이를 초전도체에 구축했습니다. 모든 스택에서 작동합니다. 리포지토리에서 PR을 선택하고, 테스트할 에이전트를 선택하고, 코드별 품질 대 비용 분석을 얻을 수 있습니다. 무료로 사용할 수 있으며 자신의 API 키나 프리미엄 플랜을 가져오기만 하면 됩니다.