엔비디아는 없나요? 괜찮아요. 내 2018년 "Potato" 8세대 i3는 16B MoE에서 10TPS를 달성했습니다.
저는 버마에서 이 글을 쓰고 있습니다. 여기서는 우리 모두가 최신 NVIDIA 4090s나 고급 MacBook을 구입할 여유가 없습니다. 예산이 부족한 경우 ChatGPT와 같은 기업 AI가 귀하를 보호하려고 노력할 것입니다. 오래된 듀얼 코어 i3에서 16B 모델을 실행할 수 있는지 묻는다면 "불가능하다"고 답할 것입니다.
나는 그들이 틀렸다는 것을 증명하는 방법을 알아내는 데 한 달을 보냈습니다.
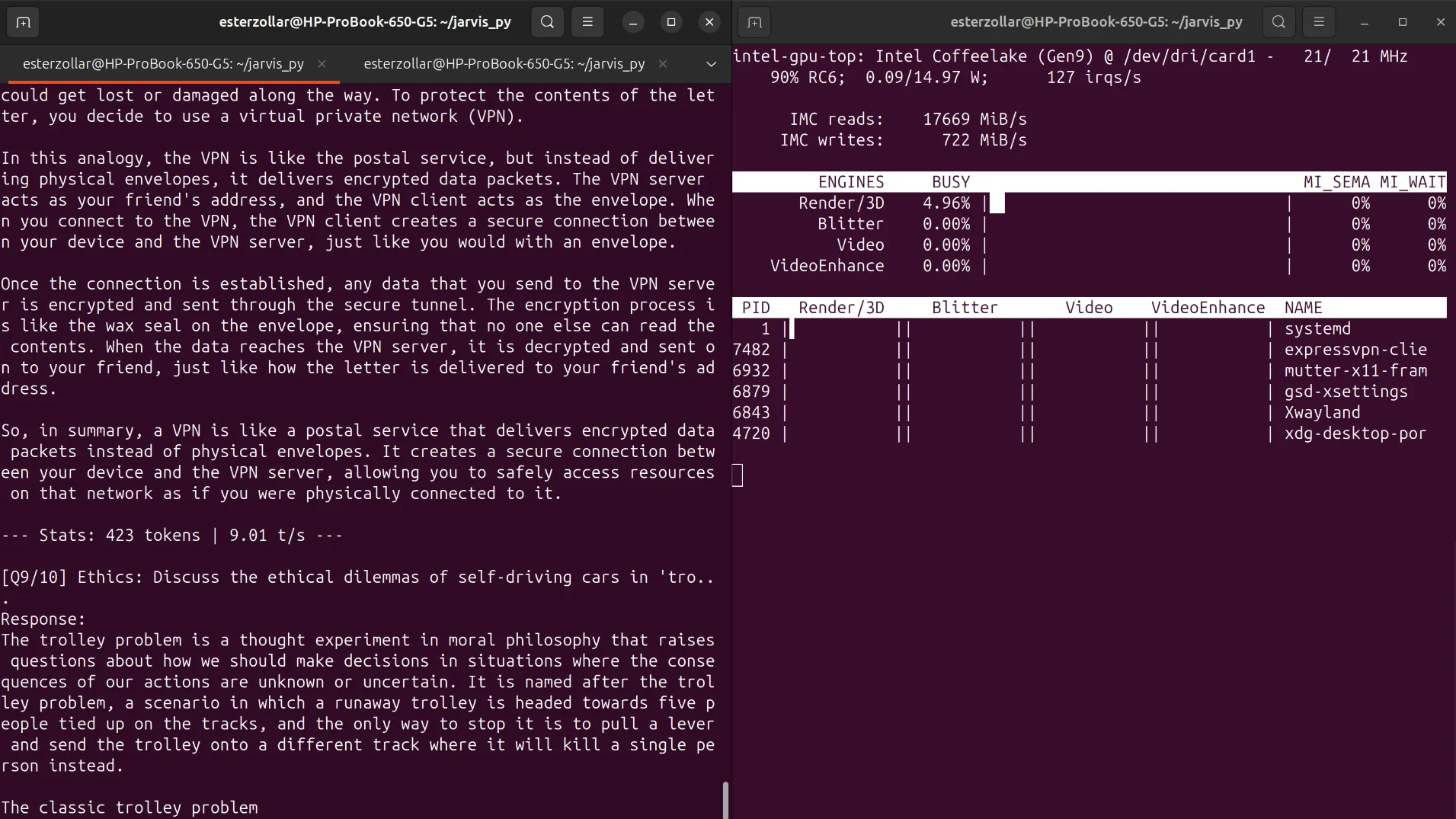
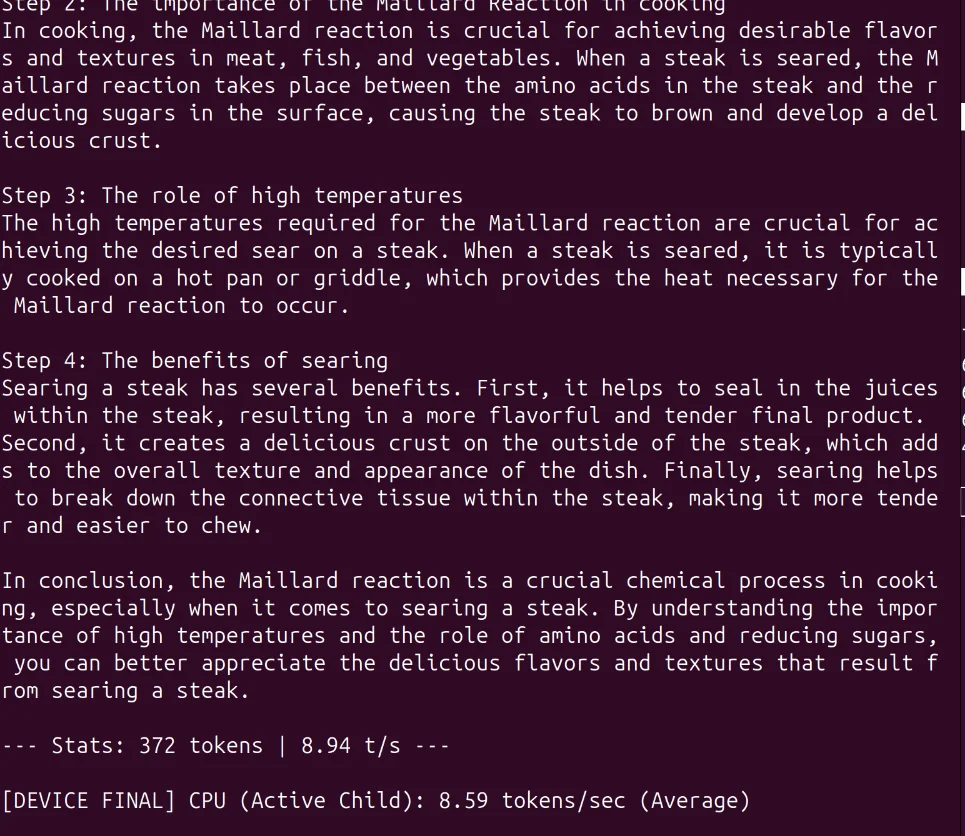
30일 동안 하드웨어의 성능 저하를 모두 제거한 후 최고점을 찾았습니다. 저는 HP ProBook 650 G5(i3-8145U, 16GB 듀얼 채널 RAM)에서 DeepSeek-Coder-V2-Lite(16B MoE)를 인간에 가까운 읽기 속도로 실행하고 있습니다.
#### 전투: CPU 대 iGPU
토큰 제한과 실시간 스트리밍 없이 20개의 질문으로 구성된 직접 테스트를 진행했습니다.
| 장치 | 평균 속도 | 최고 속도 | 내 평가 |
| --- | --- | --- | --- |
| CPU | 8.59t/초 | 9.26t/초 | 8.5/10 - 깔끔하고 견고한 논리. |
| iGPU(UHD 620) | 8.99t/초 | 9.73t/초 | 9.0/10 - 일단 따뜻해지면 짐승이 됩니다. |
결과: iGPU(OpenVINO)가 승자이며, 올바르게 설정하면 통합 Intel 그래픽도 무거운 작업을 처리할 수 있음을 입증합니다.
## 내가 어떻게 성과를 냈는지:
* MoE는 "치트 코드"입니다. 16B 매개변수는 거대해 보이지만 토큰당 2.4B만 계산합니다. 3B-4B 밀도 모델보다 빠르고 스마트합니다.
* 듀얼 채널은 필수입니다. 16GB(2x8GB)를 실행하고 있습니다. 단일 채널을 갖고 있다면 걱정하지 마세요. 대역폭이 질식할 것입니다.
* Linux는 왕입니다. 저는 Ubuntu에서 이 작업을 수행했습니다. Windows 백그라운드 프로세스는 내 "감자"가 감당할 수 없는 사치입니다.
* OpenVINO 통합: OpenVINO를 단독으로 사용하지 마십시오. 종속성 지옥입니다. llama-cpp-python의 백엔드로 사용하세요.
## 현실 점검
1. 최초 실행 지연: iGPU를 컴파일하는 데 시간이 걸립니다. 붙어 있는 것처럼 보일 수도 있습니다. 잠시만 기다려 주세요. "GPU"가 커피를 마시고 있는 중입니다.
2. 언어 드리프트(Language Drift): iGPU에서는 가끔 중국어 토큰으로 빠져나가는 경우가 있지만 논리는 결코 깨지지 않습니다.
돈이 부족해서 AI를 배우지 못하게 해서는 안 되기 때문에 이 글을 공유합니다. 내가 버마의 i3에서 이것을 할 수 있다면 당신도 할 수 있습니다.
## 설명이 편집됨
코어 llama.cpp 저장소 또는 문서에서 OpenVINO CMAKE 플래그를 찾는 경우: **아직 업스트림 코어에 없습니다**. 업스트림 llama.cpp를 직접 사용하지 않습니다. 대신 OpenVINO 백엔드가 활성화된 소스에서 빌드된 llama-cpp-python을 사용하고 있습니다. OpenVINO 지원은 기본 llama.cpp 마스터 브랜치에 병합되지 않았지만 llama-cpp-python은 이미 사용자 정의 CMake 빌드 경로를 통해 이를 지원합니다.
다음과 같이 llama-cpp-python을 설치하십시오: `CMAKE_ARGS="-DGGML_OPENVINO=ON" pip install llama-cpp-python`
벤치마크 세부 사항
명확성을 위해 벤치마크 결과는 다음과 같습니다. 이는 고정된 max_tokens=256을 사용하여 디코드 속도(사전 채우기 후)를 측정하며 n_ctx=4096으로 10번의 실행에서 평균을 냅니다.
CPU 평균 디코드: ~9.6t/s
iGPU 평균 디코드: ~9.6 t/s
내가 "~10 TPS"라고 말하는 것은 사전 채우기 속도가 아니라 디코드 TPS(초당 토큰 수)를 의미하는 것입니다.
동일한 하드웨어에서 DeepSeek-V2-Lite와 GPT-OSS-20B 간의 자세한 비교를 여기에서 확인할 수 있습니다.