30% 적은 메모리로 MoE 모델을 12배 더 빠르게 학습하세요! (<15GB VRAM)
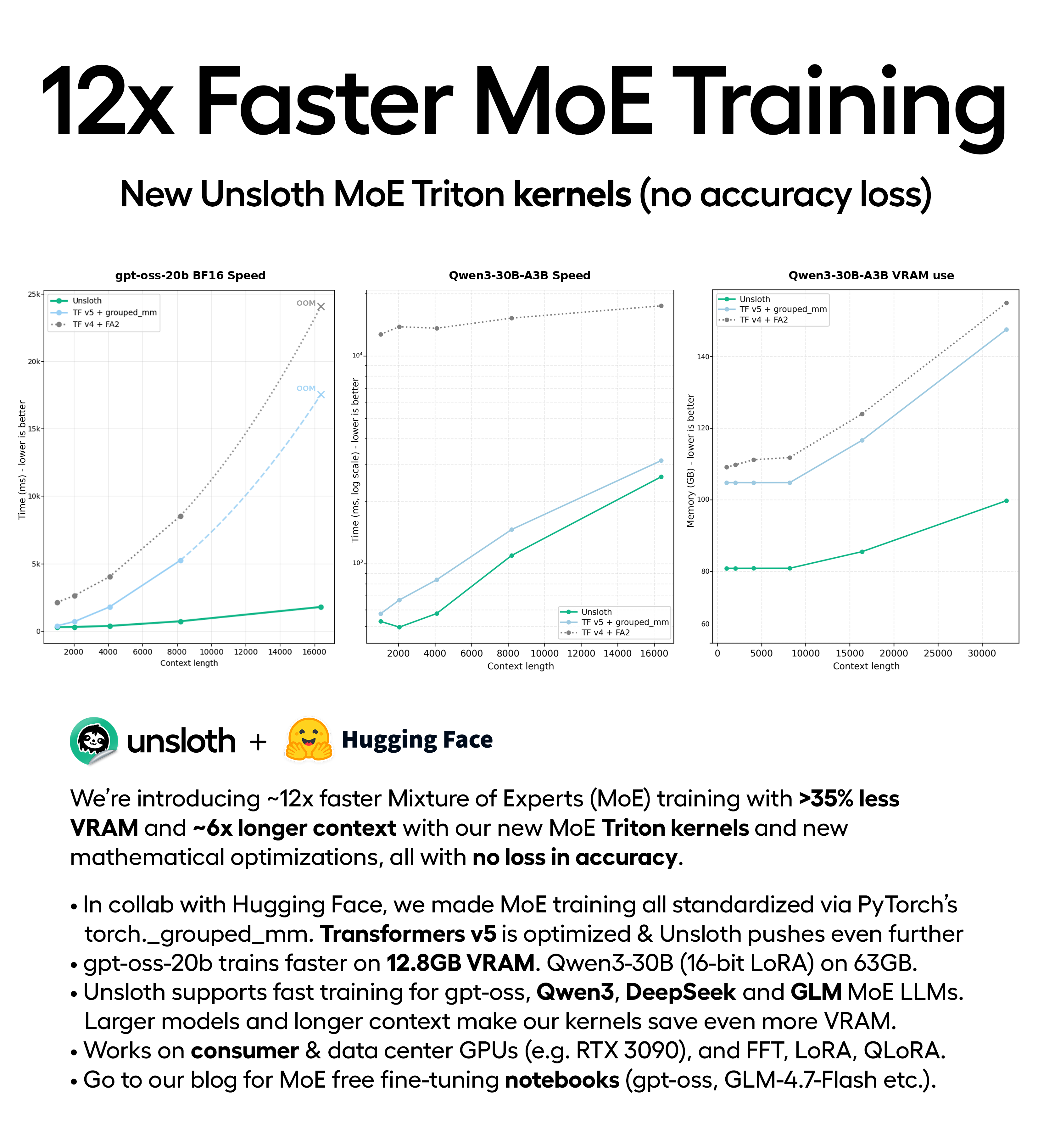
안녕하세요 r/LocalLlama! 새로운 맞춤형 Triton 커널 및 수학 최적화(정확도 손실 없음)를 통해 **>35% 더 적은 VRAM** 및 **~6배 더 긴 컨텍스트**를 사용하여 ~12배 더 빠른 전문가 혼합(MoE) 교육을 도입하게 되어 기쁘게 생각합니다. Unsloth 저장소: https://github.com/unslothai/unsloth
* Unsloth는 이제 gpt-oss, Qwen3(30B, 235B, VL, Coder), DeepSeek R1/V3 및 GLM(4.5-Air, 4.7, Flash)을 포함한 MoE 아키텍처에 대한 빠른 교육을 지원합니다.
* gpt-oss-20b는 **12.8GB VRAM**에서 미세 조정됩니다. Qwen3-30B-A3B(16비트 LoRA)는 63GB를 사용합니다.
* 우리 커널은 데이터 센터(B200, H100), **소비자** 및 이전 GPU(예: RTX 3090), FFT, LoRA 및 QLoRA 모두에서 작동합니다.
* 모델이 더 크고 사용하는 컨텍스트가 많을수록 **Unsloth 커널의 메모리 절약 효과는 더욱 뚜렷해집니다**(효율성은 기하급수적으로 증가합니다).
* 이전에 gpt-oss에 대한 Unsloth Flex Attention을 도입했으며 이러한 최적화를 통해 더욱 효율적이 될 것입니다.
Hugging Face와의 협력을 통해 우리는 PyTorch의 새로운 `torch._grouped_mm` 기능을 사용하여 모든 MoE 교육 실행을 표준화했습니다. Transformers v5는 최근 v4보다 최대 6배 빠른 MoE로 최적화되었으며 Unsloth는 사용자 정의 Triton 그룹화 GEMM + LoRA 커널을 사용하여 이를 더욱 강화하여 **추가** ~2배 속도 향상, >35% VRAM 감소 및 >6배 더 긴 컨텍스트(v4에 비해 전체 속도 12~30배 향상)를 제공합니다.
자세한 분석, 벤치마크 등을 알아보려면 교육 블로그 게시물을 읽어보세요. https://unsloth.ai/docs/new/faster-moe
최근에는 모델 미세 조정 내장에 대한 지원도 출시했습니다. 무료 MoE 미세 조정 노트북을 사용할 수 있습니다.
|**gpt-oss (20b)**-Fine-tuning.ipynb) **(무료)**|gpt-oss (500K 컨텍스트)_500K_Context_Fine_tuning. ipynb)|GLM-4.7-Flash.ipynb) (A100)|
|:-|:-|:-|
|gpt-oss-120b_A100-Fine-tuning.ipynb) (A100)|Qwen3-30B-A3B (A100)|TinyQwen3 MoE T4(무료)|
훈련을 자동으로 더 빠르게 만들기 위해 Unsloth를 업데이트하려면 Docker를 업데이트하거나 다음을 수행하십시오.
pip install --upgrade --force-reinstall --no-cache-dir --no-deps unsloth unsloth_zoo
읽어주셔서 감사합니다. 모두 즐거운 한 주 보내시기 바랍니다. 이번주는 바쁜 한 주가 될 것이라고 들었습니다! :)