NVIDIA가 아직 클러스터링할 수 없다고 말한 3개의 DGX Sparks를 클러스터링했습니다... 작동하는 데 1500줄의 C가 필요했습니다.
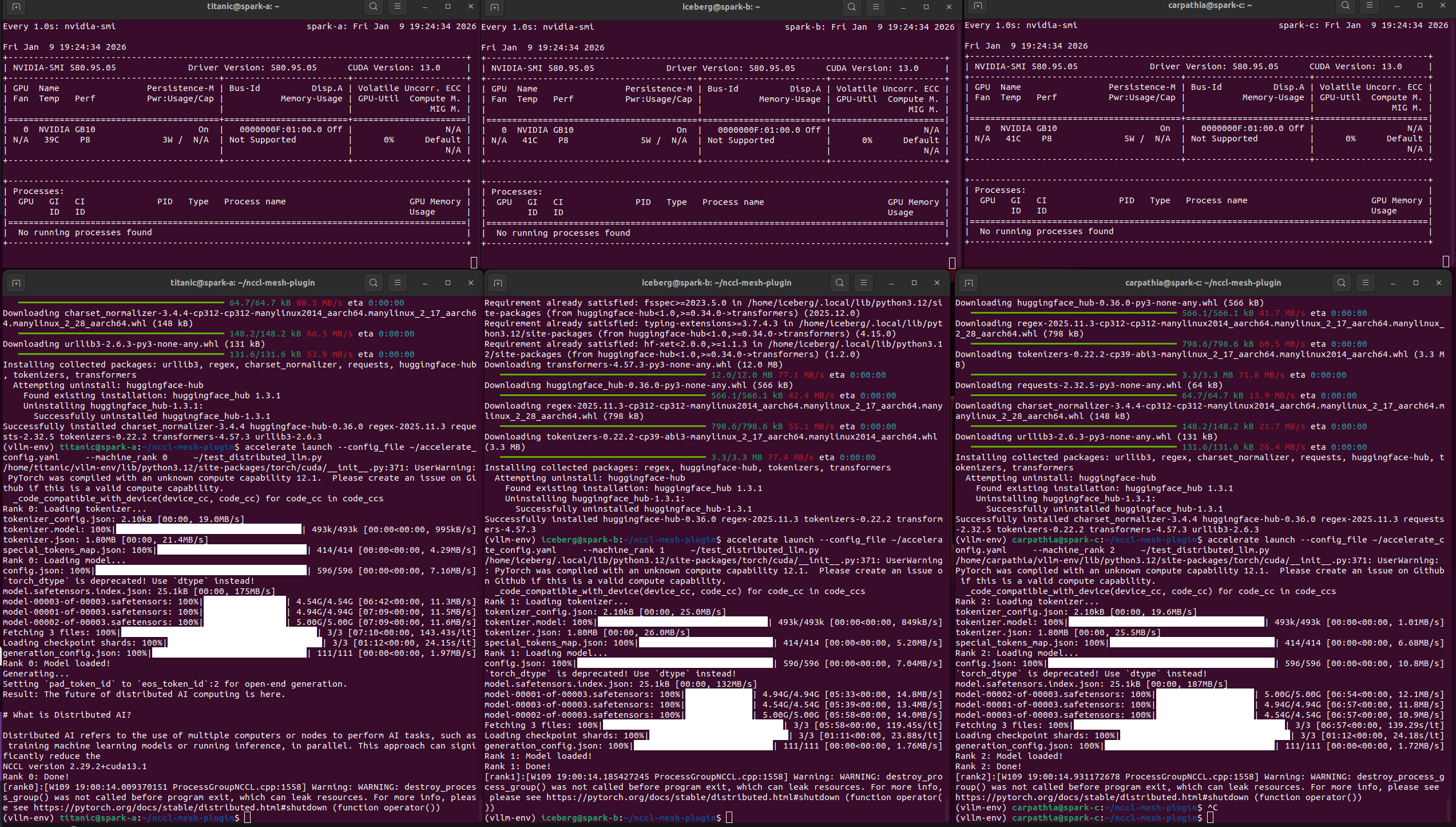
NVIDIA는 공식적으로 *두 개의* DGX Spark를 함께 클러스터링하는 것을 지원합니다. 저는 세 개를 원했습니다.
문제는 각 스파크에는 두 개의 100Gbps ConnectX-7 포트가 있다는 점입니다. 3노드 트라이앵글 메시에서 각 링크는 서로 다른 서브넷에 연결됩니다. NCCL의 기본 네트워킹은 모든 피어를 단일 NIC에서 연결할 수 있다고 가정합니다. 하지만... 작동하지 않습니다.
그래서 저는 처음부터 사용자 정의 NCCL 네트워크 플러그인을 작성했습니다.
**기능: **기능
* 서브넷 인식 NIC 선택(각 피어에 적합한 NIC 선택)
* 원시 RDMA 동사 구현(QP 상태 머신, 메모리 등록, 완료 대기열)
* 교착 상태 방지를 위한 사용자 지정 TCP 핸드셰이크 프로토콜
* ~1500줄의 C
**결과: **3개 노드 모두에서 RDMA를 통해 8GB/s 이상의 속도로 분산 추론. **현재 사용 중인 NVIDIA 지원 티어:**
├── 지원되는 구성 ✓.
├── "작동해야 함" 구성
├── "자체적으로 해결" 구성
├── "전화하지 마세요" 설정
├── "어떻게..." 구성
└── 당신은 여기에 있습니다 → "클러스터 독립 실행형 워크스테이션에
클러스터 독립형 워크스테이션에
클러스터링하기 위한 커스텀 NCCL 플러그인 작성"
깃허브 링크: https://github.com/autoscriptlabs/nccl-mesh-plugin
구현에 대한 질문에 기꺼이 답변해 드립니다. 이것은 많은 저수준 디버깅(세그 오류, RDMA 상태 머신 문제, GID 테이블 문제)이 있었지만 작동합니다.