9천 유로의 GH200 '데스크톱'을 구입하여 1.27달러를 절약했습니다(vLLM 튜닝 노트).

**요약: 클로드 코드로 완전히 로컬로 갈 수 있으며, 적절한 튜닝을 통해 결과는 *놀랍습니다*... Sonnet을 사용하면 Claude Code보다 더 빠른 속도를 얻을 수 있고 결과물의 분위기도 좋습니다. 도구 사용은 완벽하게 작동하며 연간 구독료가 MiniMax의 321배에 불과합니다!
제 블로그 게시물에서 듀얼 96GB 시스템용 도커에서 vLLM을 시작하기 위한 최적화된 설정과 이 설정을 MiniMax M2.1과 함께 사용하여 완전한 오프라인 코딩(원격 측정 및 모든 불필요한 트래픽 차단 포함)을 위해 Claude Code를 시작하는 방법을 공유했습니다.
---
좋아요, r/LocalLLaMA 여러분, 모여주세요.
저는 지극히 정상적인 재정적 책임 행위를 저질렀습니다: 9000유로(아니, 아내에게 미리 알리지 않았습니다)를 들여 2× GH200 96GB 그레이스호퍼 "데스크탑"을 구매한 다음, **클라우드 코드**가 **~140GB** 로컬 모델을 사용할 수 있도록 일주일 동안 **vLLM**을 튜닝하는 데 시간을 보냈습니다.
그 결과, 이제 제 컴퓨터는 로컬에서 코드 리뷰를 생성하고 제가 본 것 중 가장 재미있는 회계 대사를 생성합니다.
여기 "야수"가 있습니다(위 링크에서 컴퓨터에 대한 배경을 읽어보세요).
2× GH200 96GB (따라서 **총 **192GB VRAM**)
* 토폴로지는 '시스템', 즉 *NVLink*가 없고 PCIe/NUMA 분위기만 있습니다.
* 기존의 통념: "NV링크 없음 ⇒ 파이프라인 병렬"
* 나: "인터넷의 가이드는 나를 배신하지 않을 것"
독자 여러분, 가이드가 저를 배신했습니다.
저는 클로드 오푸스의 조언에 따라 -pp2 모드 "파이프라인 병렬"을 사용했습니다. 결과는 꽤 좋았지만 시스템을 실제로 조정하기 위해 많은 벤치마킹을 하고 싶었습니다. 이 vLLM 설정은 (제 특별한 이상한 설정에 대해) 매우 효과적이었습니다:
* ✅ **TP2**: `--텐서-병렬 크기 2`: `--텐서-병렬 크기 2`
* ✅ **163,840 컨텍스트** 🤯
* ✅ `--max-num-seqs 16`, 이 노브 하나로 클로드 코드가 스포츠카처럼 느껴질지 팩스처럼 느껴질지를 제어하기 때문입니다.
* ✅ 청크 미리 채우기 기본값(`8192`)
* "유휴 후 첫 번째 요청" 점프 스케어 방지를 위해 ✅ `VLLM_SLEEP_WHEN_IDLE=0` 설정
***192GB VRAM*** *시스템에 맞게 튜닝된 MiniMax-M2.1 FP8+INT4 AWQ 퀀트에 대해 * ***mratsim***에게 감사드립니다.* * **절대 전설** 🙏
그의 리포지토리를 확인하세요: https://huggingface.co/mratsim/MiniMax-M2.1-FP8-INT4-AWQ; 그는 다른 무거운 모델을 위한 놀라운 ExLlama v3 퀀트도 보유하고 있습니다.
그는 미니맥스-M2.1을 192GB 설정으로 최대한 잘 실행되도록 신중하게 튜닝했습니다. 그 이상이면 더 큰 퀀트를 사용하지만, 더 큰 모델(GLM4.7, DeepSeek 3.2 또는 Kimi K2)은 더 엄격한 퀀트를 사용하거나 REAP을 사용하고 싶지 않았습니다.
**파이프라인 병렬(PP2)은 저를 구하지 못했습니다**.
'시스템' 토폴로지(일명 "통신은 고통이다")에도 불구하고 **PP2는 페이스플랜트**했습니다. 조금 더 배경을 설명하자면, 제가 이 시스템을 구입한 것은 매우 슬픈 상태이지만, 큰 문제 중 하나는 이 시스템이 랙에 살아야 하고 거대한 NVLink 하드웨어와 함께 묶여 있어야 한다는 것이었습니다. 이것이 빠져서 PCIE5 속도로 실행하고 있습니다. 여전히 훌륭하게 들리지만 900GB/s에서 125GB/s로 떨어졌습니다. 모든 가이드를 따랐지만:
* PP2가 **163k** 컨텍스트에서 시작할 수 없음(KV 캐시 할당이 vLLM을 충돌시킴).
* 114k**로 낮추었더니 시작되었습니다...
* ...그리고 여전히 **웨이 느립니다**:
* short_c4: **~49.9 tok/s** (TP2는 ~78)
* short_c8: **~28.1 tok/s** (TP2는 ~66)
* TTFT 테일은 *더 느려짐* (수초 워밍업/단축 테스트)
정말 놀랍습니다! 제가 읽은 모든 글에서 이렇게 해야 한다고 했어요. 그러니 얘들아, 항상 채소를 먹고 벤치마킹을 해보세요!
# 지급금
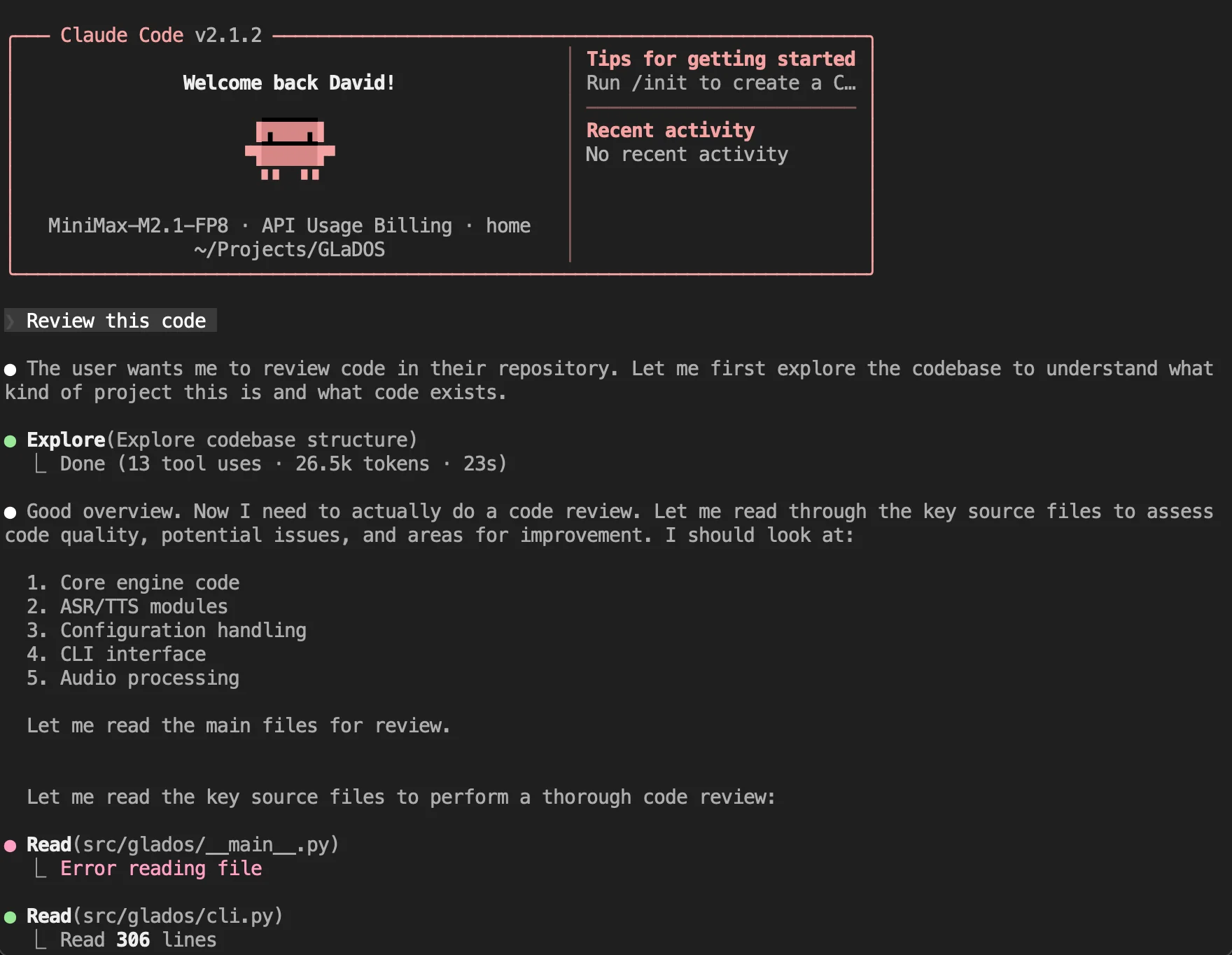
MiniMax M2.1을 사용하여 Claude Code를 실행하고 GLaDOS의 리포지토리에 대한 검토를 요청했는데, 여러 가지 문제를 발견하고 코드를 조롱한 후 다음과 같이 인쇄했습니다:
총 비용: $1.27(알 수 없는 모델 사용으로 인해 비용이 부정확할 수 있음)
총 소요 시간(API): 1분 58초
총 지속 시간(벽) 4m 10초
모델별 사용량
MiniMax-M2.1-FP8: 391.5k 입력, 6.4k 출력, 0 캐시 읽기, 0 캐시 쓰기($1.27)
어쨌든, 이 상자에 9,000유로를 지출하면 **$1.27**를 절약할 수 있습니다.
손익분기점까지 몇 천 건의 리포지토리 리뷰만 남았습니다. 💸🤡