LocalLLaMA
멀티 GPU 설정을 위한 llama.cpp 성능 혁신
익명유저1071·1개월 전·조회 316
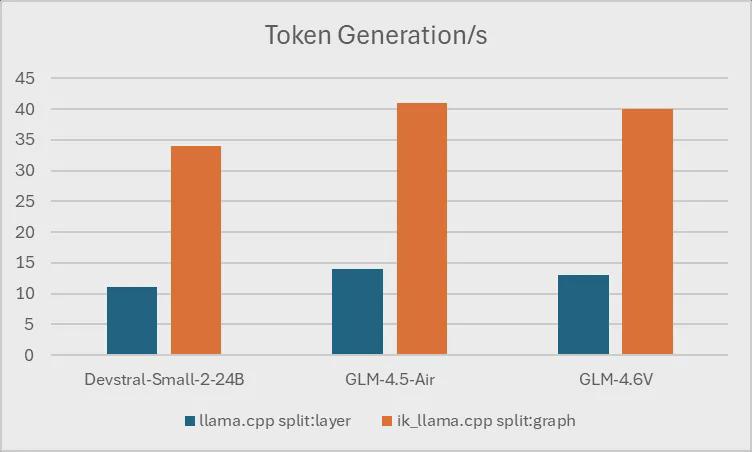
연말에 충분한 휴식을 취하고 있는 동안 **ik_llama.cpp** 프로젝트(llama.cpp의 성능 최적화 포크)는 멀티 GPU 구성에 대한 로컬 LLM 추론에서 획기적인 성과를 달성하여 소폭의 성능 향상뿐 아니라 3배에서 4배의 속도 향상이라는 엄청난 성능 도약을 이뤄냈습니다.
이전에도 로컬 모델을 실행하기 위해 여러 GPU를 사용할 수 있었지만, 이전 방식은 사용 가능한 VRAM을 풀링하는 데만 사용하거나 성능 확장이 제한적이었습니다. 하지만 ik_llama.cpp 팀은 여러 GPU를 동시에 최대로 활용할 수 있는 새로운 실행 모드(분할 모드 그래프)를 도입했습니다.
이것이 왜 중요한가요? GPU와 메모리 가격이 사상 최고치를 기록하고 있는 상황에서 이는 획기적인 변화입니다. 이제 더 이상 고가의 하이엔드 엔터프라이즈 카드가 필요하지 않고, 홈랩, 서버실 또는 클라우드에서 여러 대의 저비용 GPU의 집단적 성능을 활용할 수 있습니다.
*자세한 내용은 *여기*에서 확인할 수 있습니다.